
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 코너 검출
- difference of gaussian
- Machine Learning
- spaceship titanic
- Computer Vision
- random forest tree
- kaggle
- 이미지 처리
- 가우시안 필터
- 인공지능
- corner detection
- feature matching
- harris corner detection
- 머신러닝
- Ai
- kaggle titanic
- Random Forest
- feature descriptor
- data science
- classification
- XGBoost
- 컴퓨터비전
- 캐글
- decision tree
- 해리스 코너
- 인공지능대회
- blob detection
- 데이터사이언스
- Image Processing
- ai competition
- Today
- Total
이것저것
[Computer Vision] SIFT and Feature Matching 본문
Recap: Blob detection
지난 포스팅에서는 feature point중 하나인 blob에 대하여 살펴보았다. Blob은 이미지에서 주변과 비교했을때 intensity가 다른 영역을 의미한다. Blob을 감지하는 방법은 우선 2D Gaussian function의 Laplacian을 계산한 후 standard deviation의 제곱을 곱하여 scale-normalize를 하고 이 2d filter를 이미지에 convolve를 하였을때의 local maxima를 찾는다. 이때 scale space에서 local maxima들중 가장 response가 큰 optimal sigma가 정해지며, $\frac{\sigma}{\sqrt{2}}$ 가 blob의 radius 가 된다. 하지만 LoG를 사용하기보다는 서로 다른 standard deviation을 가진 gaussian filter 두개의 차이를 활용한 DoG가 LoG를 잘 approximate 하여 이미지 처리 속도를 향상시킬 수 있다. 이렇게 완성된 feature point들은 corner와는 다르게 scale invariant 하다. Corner를 scale-invariant한 feature point로도 바꿀 수 있는데, Harris corner detection을 사용해 코너를 검출한후 각각 다른 sigma의 LoG 필터를 적용해 maximum response를 찾으면 이때의 optimal sigma를 알 수 있고, scale 까지 알아낼 수 있다 (Harris-Laplace). 두 방법 모두 blob이 원으로 나오는데, 이미지에서 affine transformation 이 일어나면 원 역시 타원으로 변형되어야 한다. 따라서 affine covariance를 따르기 위하여 second moment matrix를 사용해 원을 타원으로 transform 한다.
Feature descriptor
지난 포스팅까지는 corner나 blob같은 feature를 이미지에서 detect하는 방법에 대하여 다뤄왔다. 앞으로는 같은 사물을 다른 시점에서 찍은 사진에서 두 이미지의 feature point를 가지고 feature들을 matching 하는 방법에 대하여 이야기 하고자 한다.

Blob이 scale-invariant 하니까 모든 feature point들은 blob 이라고 생각하고 시작해보자. Affine covariant 한 feature point들은 타원 형태를 가지고 있기 때문에 모양이 제각각이다. 따라서 inverse afifne transformation을 하여 원형으로 바꾼다. 이때 타원에서 unit circle로의 transformation은 고유하지 않기 때문에 rotational ambiguity가 발생한다.
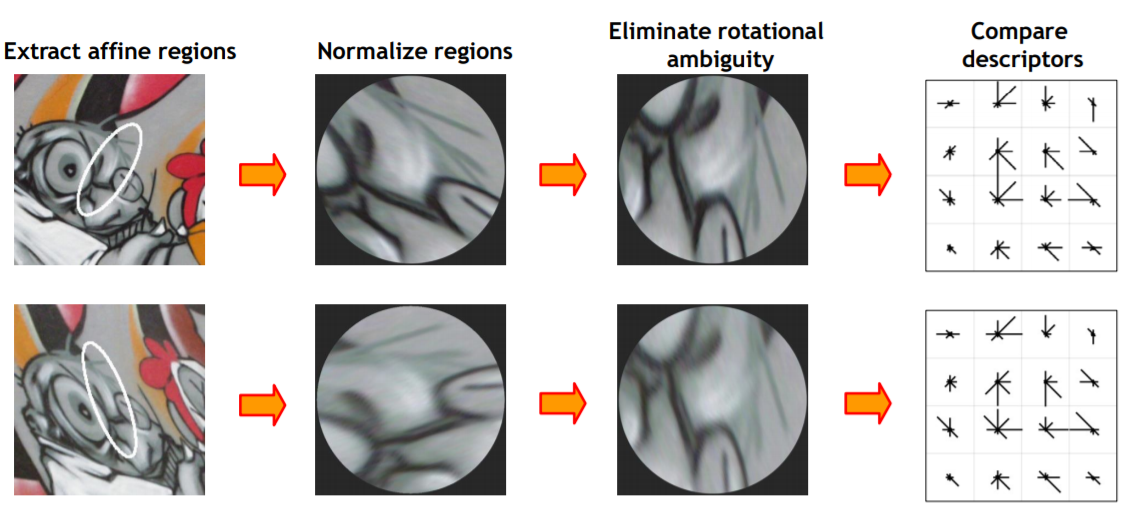
위 사진을 보면 같은 feature point라도 affine normalize를 하게 되면 rotational ambiguity가 생기는걸 볼 수 있다. 그러면 unit circle을 돌려 두 feature point가 같은 방향을 바라보도록 rotational ambiguity를 제거하여야 한다. 이때 히스토그램을 사용한다.
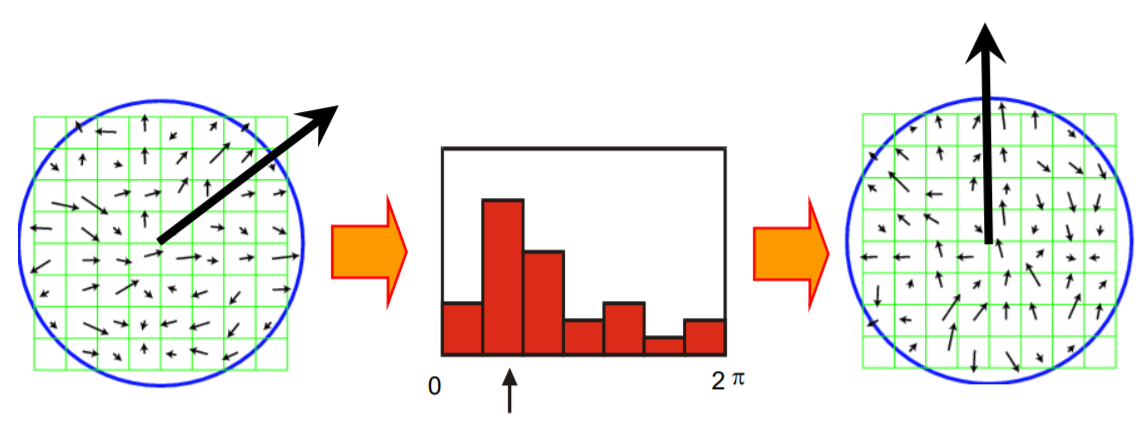
Feature point에서 각 지역의 gradient를 계산한 다음 (sobel filter를 주로 사용) 가장 dominant 한 방향을 위를 향하게 고정시키면 rotational ambiguity를 가진 두 feature point가 정확히 맞아떨어지게 된다.
Scale Invariant Feature Transform (SIFT)
Feature description에서 가장 유명한 알고리즘이다. 1999년 David Lowe가 고안해 내었으며 2021년에는 citation이 64000번일 정도였다.
우선 DoG를 이용하여 scale-invariant 한 feature point들을 detect한 후 feature point를 향상시키기 위하여 post-processing을 한다 (position interpolation, discard low-contrast points, eliminate points along edges 등). 그 다음 rotation ambiguity를 제거하기 위해 히스토그램을 사용하여 dominant orientation을 찾고 알맞은 방향으로 feature point를 회전시킨다.

하지만 feature point가 각각 다른 pixel 개수를 가지고 있으므로, 위의 이미지를 보면 center point를 중심으로 한 16 * 16 이미지로 으로 resample을 한다. 이때 256개의 픽셀을 4*4의 크기로 16개로 나누고 각각 4*4 grid의 gradient를 히스토그램으로 표현한다. 이때 gradient 값은 continuous 하므로 360도를 8개의 bin으로 나누어 히스토그램을 만든다. 그러면 결과적으로 4*4 grid에 8개의 bin이 있으므로 히스토그램의 frequency를 담은 128차원 벡터를 만들어 낼 수 있다. 이 128차원 벡터를 normalize하면 feature point의 정보를 담은 feature descriptor가 된다. 만약 두 feature point가 유사한 feature descriptor를 가지고 있다면 같은 지점을 나타낼 가능성이 크다는 것이다.
하지만 한가지 문제가 있는데, specular reflection이 된 픽셀 역시 blob으로 판단하고 feature descriptor를 얻어내 같은 점으로 매칭될 수 있다. 하지만 specular reflection의 위치는 보는 방향에따라 달라지기 때문에 feature point가 될 수 없다. 이 문제를 해결하기 위해 normalize 된 descriptor에서 threshold 값 이상인 값들을 threshold 값으로 맞추고 re-normalize를 하면 문제를 해결할 수 있다. 이때의 threshold는 보통 0.2로 맞춘다.
Feature Matching
첫번째에서 본 그림과 같이 어떤 한 물체를 서로다른 두 위치와 배경에서 촬영하였을때 특징점들을 match 시키는 것을 feature matching 이라고 한다. 특징점들은 이전 포스팅에서 다루었던 Blob detection이나 Harris-Laplace 등을 사용하여 찾을 수 있었고 특징점을 수치적으로 나타내는 feature descriptor extraction을 SIFT를 사용해서 알아보았다. 두 feature point의 descriptor가 비슷하면, 즉 histogram의 모양이 비슷하면 두 포인트는 대응한다고 할 수 있는 것이다. 따라서 두개의 히스토그램의 모양이 얼마나 비슷한지를 나타내는 양을 어떻게 측정할지부터 생각해 보아야 한다. 히스토그램의 유사도를 측정할때는 histogram distance를 사용하는데 distance가 작을수록 높은 유사도를 나타낸다. Histogram distance에서는 histogram intersection, chi-squared distance, EMD가 대표적이다.
Histogram Intersection

$$histint(h_i, h_j) = 1-\sum_{m=1}^{k} min(h_i(m), h_j(m)) $$
histint 함수는 두 히스토그램의 intersection 구간을 측정한다. 많은 intersection이 있다면 두 히스토그램이 비슷하다고 할 수 있다.
$ \sum_{m=1}^{k} min(h_i(m), h_j(m)) $ 부분이 히스토그램의 intersection을 측정하고, 1에서 빼준 이유는 histogram intersection이 클수록 유사하다는 의미이고 따라서 distnace가 작아져야 하기 때문이다.
Chi-squared distance
이름 그대로 expected value와 observed value의 discrepancy를 나타내는 $\chi^2$-statistic 과 같은 맥락이고, 식도 비슷하다.

$$ \chi^2 = \frac{1}{2} \sum_{m=1}^k \frac{[h_i(m)-h_j(m)]^2}{h_i(m)+h_j(m)} $$
마찬가지로 $\chi^2$ 값이 작을수록 유사하다.
Earth-mover Distance (EMD)
EMD는 히스토그램 A 에서 히스토그램 B로 변환시키는데 드는 "일의 양"의 최솟값 이라고 생각하면 된다. 물리에서 F가 일정하고 1차원에서 일의 양은 $ W=Fs $ 인데 이와 같은 맥락으로 amount moved * distance moved로 계산하면 된다. 마찬가지로 EMD가 낮을수록 유사도가 높다.

SIFT Feature Matching
SIFT를 사용할때 간편한 또다른 histogram distance는 Euclidean Distance와 cosine simularity 이다. Euclidean distnace는 128D space에서 histogram vector 두개를 연결해주는 벡터의 L2 norm을 계산하면 된다. Cosine similarity는 두 128D 벡터 사이의 각도의 코사인 값을 나타낸다. Inner product를 각 벡터의 L2 norm으로 나눠주면 된다.
하지만 여기서 문제는 두 이미지에서 검출한 feature point들이 모두 match를 가지지 않는다는 점이다. Feature point들은 각 이미지에서 독립적으로 추출되었기 때문에 feature matching을 할때 bijection이라는 보장이 없다. 따라서 injection/surjection을 고려해보면 match 가 없는 feature point들을 검출하기 위해 Euclidean Distance가 일정 값 이하가 되는 pair만 매칭을 시키면 되지 않을까라는 생각이 든다. 하지만 threshold value가 이미지마다 다를기 때문에 어떤 상수 하나를 지정하기 쉽지 않다. 따라서 나온 방법이 가장 가까운 점과 두번째로 가까운 점의 거리 비율을 계산하는 nearest neighbor distance ratio (NNDR)이다.
$$ NNDR = \frac{NND1}{NND2} $$
위의 식에서 NND1은 첫번째로 가까운 점이고 NND2는 두번째로 가까운 점이다. 만약 한 점이 다른 점보다 압도적으로 distance가 작다면 NND1의 값이 매우 작고 NND2의 값이 매우 클것이므로 NNDR은 0에 가까워진다. 만약 두 점이 distance 가 비슷하다면 NND1과 NND2의 값이 비슷할 것이고 NNDR은 1에 가까워진다. 따라서 NNDR이 0에 가까운 점들은 매칭이 확실하게 된다고 생각할수 있기 때문에 NNDR에 constant threshold를 걸어주는 방법이 더 올바르다고 할 수 있다. 보통 NNDR은 0.75로 설정하고 0.75 이하의 점들만 골라보면 된다고 한다. 아래 그래프는 SIFT 창시자인 David Lowe의 논문에서 나온 그래프이다. NNDR이 0.75를 넘어가면 incorrect match의 PDF가 급격하게 올라가는 것을 확인할 수 있다. (Reference 참조)

Reference
KAIST MinHKim CS484 Introduction to Computer Vision
https://docs.opencv.org/3.4/dc/dc3/tutorial_py_matcher.html
OpenCV: Feature Matching
Goal In this chapter We will see how to match features in one image with others. We will use the Brute-Force matcher and FLANN Matcher in OpenCV Basics of Brute-Force Matcher Brute-Force matcher is simple. It takes the descriptor of one feature in first se
docs.opencv.org
https://hygenie-studynote.tistory.com/47
Rotation, Scale, Affine Invariant Features
* 이 포스트는 컴퓨터 비젼에 대한 개인 학습용으로 작성한 포스트입니다. Invariant Features 일반적으로 컴퓨터비젼에서는 3개의 문제가 존재한다. 1. Detection : 특징 포인트를 어떻게 찾을 것인가? 2.
hygenie-studynote.tistory.com
리디렉션 알림
www.google.com
David Lowe's paper
'Computer Vision' 카테고리의 다른 글
| [Computer Vision] BoVW Scene Recognition and Spatial Pyramid (2) | 2025.01.15 |
|---|---|
| [Computer Vision] Blob Detection (2) | 2024.12.28 |
| [Computer Vision] Harris Corner Detection 해리스 코너 검출 (5) | 2024.12.27 |


